リアルタイム物体検出向けニューラルネット、SSD(Single Shot Multi Detector)及びその派生モデルの解説
さて、昨年行ったGTC Japan 2017では物体検出のデモを行っているブースが多く、盛り上がりを見せている分野と感じています。
たしかに、物体検出のデモってすごくAI感(?)があります。
今回の記事はリアルタイム(~0.1sec)物体検出に使われるSSD及びその派生モデルのお話。

[1]SSD検出結果
物体検出の難しさ
物体検出の難しさはいかにして、アスペクト比や大きさが違う複数の物体が存在しそうな候補領域を正確に、スピーディーに抽出するか?にあるといえます。
候補領域さえ決めればあとは分類問題でしかありません。
候補領域を提案するアルゴリズムとして、スライディングウィンドウやセレクティブサーチなどがありますが、計算量がいかんせん多い。
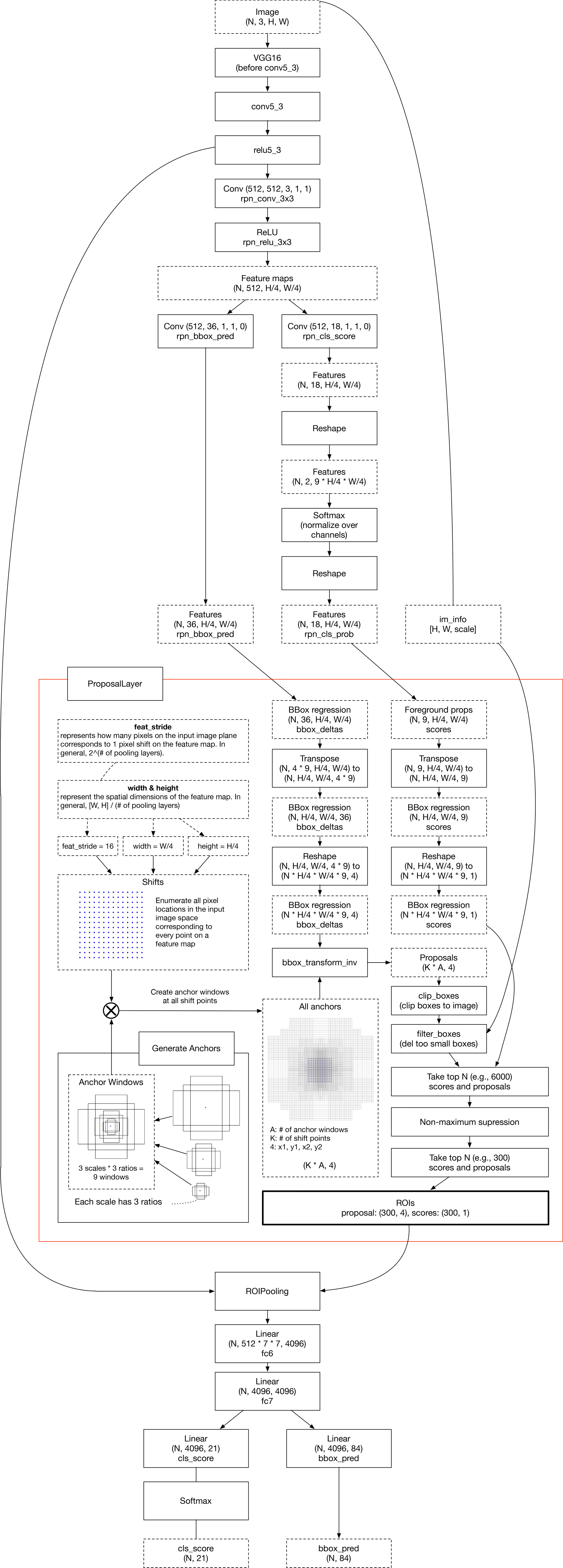
その課題意識から、ニューラルネットに分類だけでなく候補領域の提案まで行わせる、Fast RCNNやFaster RCNNが出てきました。

[2]Faster RCNN
SSD
SSDは、Faster RCNNより後にあらわれた、Faster RCNNより高速で性能が高いネットワークです。Faster RCNNとSSDの最も大きな考え方の違いは、
前者がSingle Scale Feature mapにMulti scale anchor box(さまざまな大きさの候補領域)を適用させているのに対し、後者がMulti scale feature mapを使用していることでしょう。

[2] Faster RCNNでは各feature map に複数のサイズのanchor boxを使う。

[1] Multi Scale Feature mapでは複数のFeature mapを使う。
多層CNNでは、Convolution LayerやPooling LayerでFeature mapがダウンサンプリングされて後段に行くほどFeature mapのgrid数が少なくなる(1つのgridサイズが大きくなる)ので、それぞれの層のFeature mapには色々なサイズの物体を検出できる情報があるはずじゃん!というわけです。
つまり、後段のFeature mapの各グリッドでは大きな物体の情報、前段の各グリッドでは小さな物体を取ることができるということ。
そして、各グリッドのfeatureを使って、アスペクト比、クラス、オフセットを予測させます。
ネットワーク構造

[1]SSDのネットワーク構造
SSDではVGG16をベースとして、追加のConvolution LayerとPrediction Layer(位置オフセットとクラスを予測するモジュール)が接続されています。
{kind=link}
この図のFaster RCNNのRegional Proposal Networkと比べて、convolutionレイヤーが数層あるのみと、Region proposal(候補領域抽出)はシンプルにできていることがわかります。
また、トレーニング過程でもいくつか工夫されたテクニックが使われています。
マルチボックスマッチング
ベストマッチした(もっともエリアが重複している)バウンディングボックスだけを正解とするのではなく、Jaccard Overlapが50%以上のものを学習させてます。
ただし、後述するsmooth L1 Lossにより、より提案領域が近いバウンディングボックスほどロスが小さくなっていきます。
default boxと回帰によるオフセット予測
さて、画像の中には様々なアスペクト比の物体が存在します。ですので、各Feature mapのgridに対して、複数のアスペクト比のバウンディングボックス(例えば縦横が3:1,2:1,1:1,1:2,1:3)を候補として提案させます。
また、アスペクト比だけでなく、デフォルトボックスを中心とする提案領域は物体と中心位置や幅が合っていないことがあります。
そこで、幅、高さ、位置(縦、横)の4成分に回帰するConvolution layerを追加します。
ハードネガティブマイニング
典型的な画像の多くの面積は背景によって占められています。ナイーブにすべてのバウンディングボックスについて毎回学習を行うと、極端な話背景しか出力しないネットワークでもある程度ロスを下げることができてしまい、検出力の低いモデルになってしまいます。
そこで、物体ラベルが存在するバウンディングボックス:存在しないバウンディングボックスの比が3:1になるように選び、それらについてロスを計算します。
ロス関数
SSDのロス関数はオフセットの回帰ロスと分類ロスの合計です。
前者はFaster RCNNに使われているSmooth L1 function、後者は普通にSoft Max Cross Entropyが使われています。
データオーグメンテーション
画像を歪ませたり、画像のズームアウト、画像のクロッピング、水平方向のフリップが使われています。
DSSD(Deconvolutional Single Shot Detector)の登場
SSDですが、画像のサイズに対して小さい物体を検出しづらいという欠点があります。これは小さい物体を検出するレイヤほど浅めのレイヤであり、特徴量を抽出しきれていないことによるものです。
そこで、SSDの進化系ではいかに深いレイヤの情報を使って小さい物体を検出するかが課題となっています。
Deconvolutional Module

[2]DSSDのネットワーク構造
DSSDではSSDの後段にDeconvolutional Module(上図の赤いレイヤ)を追加してFeature mapを(1x1)→(3x3)→(5x5)とアップサンプリングすることによって、小さいグリッドに対して、奥の特徴量を使うようにしています。
そしてDeconvolution layerと元のFeaturemapを下図のように作用させてPrediction moduleに接続します。

ResNetを使う。
VGG16よりもResNet101の方が分類性能が高いので、物体検出にもResNetを使ったほうがよいという発想です(その分計算量は増えますが)。
ただしSSDの著者がgithubで語っているように、あるいはDSSDの論文で触れられているように[3]、素のSSDではVGG16をResNetに取り替えても性能は上がりません。Resnetで性能を上げるために、後段にDeconcolutionを追加する必要があったようです。
Prediction Moduleの変更

[3]SSDのPrediction module

[3] Residual layerを使ったPrediction Module
SSDではFeature layerに直接offsetとclassを予測するConvolutionレイヤーを一つずつ接続しているだけなのに対し、Feature layerの後ろにResidual Layerを設けます。SSDにこれを足すだけでも0.7%mAPが上昇します。
Default Box増やした
シンプルですが、データセットの正解ラベルのアスペクト比の統計を取り、DSSDでは比率1:1.6のDefault boxを足しました。また(3:1, 2:1, 1.6:1, 1:1, 1:1.6, 1:2, 1:3)のすべてのアスペクト比をすべてのレイヤで使っています。
SSDでは微妙に1:3の比を使わないレイヤもあり計算量をケチっているのに対し、DSSDではじゃぶじゃぶ使っていくスタイルです。
ESSD
SSDよりも検出力が高いDSSDですが、その分予測の計算時間が伸びてしまいました。
DSSDに対して検出力を向上させつつ、計算速度を上げたのがESSDです。
ESSDではやっぱりVGGを使う。
ResNetを使うと計算量と時間が増えるのでESSDではVGG16を使っています。
隣接したFeatureMapとの和を使う
さて、ESSDのネットワーク構造はこの図です。

[4] ESSDのネットワーク構造
図からわかるように、conv10_2とconv11_2、この2つのFeature mapに対してはなにもしておりません。計算量を気にしてる感が伝わります。
Conv4_3~Conv8_2については、一つ後段のFeature mapと接続することで、予測に使える特徴量を増やしています。

[4] ESSD Extension module
後段のFeature mapとの接続にはDSSDのDeconvolutin moduleに似たExtension moduleと呼ばれるレイヤが使われます。
Prediction Moduleは追加のconv一つのみ
Residual layerを使ったPrediction moduleは計算量が大きいので、Convolution layerを一つだけ足します。これだけでもmAPが0.4%上がるので、コスパが高い。
このアーキテクチャだけで、DSSDよりも性能が上がる理由は私にはよくわかりませんが、ESSDではもうひとつ、トレーニングの工夫を行っておりこれが効いているのではないかと考えます。
Trainingを三段階にわけて行う
すなわち、ベースのSSDのみでまず学習を行い、次にSSDの重みを固定して、ESSDでの追加レイヤーのみ学習。最後にすべてのレイヤーの重みを動かすファインチューニングを行います。
RefineDet
時期的にはESSDより先だったりしますが、(今回紹介する)SSD系で最も進化しているのがRefineDetです。すなわち、ESSDよりも高速で性能が高いということです。
RefineDetはARM(Anchor Refinement Module)とODM(Object Detection Module)に分かれており、前者は粗い予測をするモジュール(後述するTwo-stage Cascaded RegressionとNegative Anchor Filteringに使用)で、後者はARMの出力を受け取り最終的な予測をするモジュールです。
そして、2つのモジュールはTransfer Connection Blockで接続します。

[5]RefinDet
この図でわかる通り、TCBの出力を二方向にすることによって、奥のConv層のFeature mapが持つ情報を前段のFeature mapに輸送できています。DSSDと似てる。
RefineDetでは以下の3つのテクニックを使っています。
TCB(Transfer Connection Block)

Deconvolution moduleと似てます。
Two-Step Cascaded Regression
ARMでもオフセットを回帰させ、ODMでさらにARMで得たオフセットに対するオフセットを回帰する、二段階を踏んで学習を行っています。
トレーニング過程では、ARMとODMそれぞれの回帰ロスの合計を使用します。
これにより、(特に小さな物体に対して)より正確なサイズ、オフセット補正を可能としています。
Negative Anchor Filtering
ARMではなんらかの物体があるかないかだけを出力させ、ODMではどのクラスかまでの予測を行います。このとき、ARMでほぼほぼ確実に物体がないと予測されたバウンディングボックスに対しては、閾値で弾いてしまいます。これによってODMではある程度物体がある可能性があると判断された領域のみの分類に専念させます。
(SSDで使っているHard Negative MiningはODMに対して使用されています。)
さて、以上の説明だけではなぜDSSDより(そしてESSDより)計算量が少ないのかわからないと思います。
実は使うFeature mapの数をケチっています。他のSSD系は6層のFeature mapを使っているのに対し、RefineDetでは4層のみを使用して計算量を削っています。
それから、default boxも微妙にケチっており、アスペクト比1:3および3:1のバウンディングボックスは使わないといった、地道な努力をしています。
まとめ
最後に各SSDの性能を表にまとめます。ただし、ここでは入力300pixel付近のもののみ。
| base | 入力サイズ | fps | mAP(VOC2007) | |
| SSD | VGG16 | 300x300 | 46 | 77.2 |
| DSSD | ResNet | 321x321 | 9.5 | 78.6 |
| ESSD | VGG16 | 300x300 | 25 | 79.4 |
| RefineDet | VGG16 | 320x320 | 40.3 | 80 |
| YoloV2 | Darknet-19 | 544x544 | 40 | 78.6 |
RefineDetつええ。
参考文献
[1] [1512.02325] SSD: Single Shot MultiBox Detector
[2] [1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[3] [1701.06659] DSSD : Deconvolutional Single Shot Detector
[5] [1711.06897] Single-Shot Refinement Neural Network for Object Detection